.svg)
An error isn't (always) an exception
Insights for developers from Swan's front-end team.
500,000
homeowners communities managed
80%
of property managers in Spain using it
40%
reduction of banking cost for communities


In most programming languages, the default way to alert that something went wrong is to throw an exception. This interrupts the regular flow of the program until, as it crawls up the call stack, it meets a piece of code that handles exceptions in the call stack, thus leaving the happy path. If you’re unlucky, the error is unhandled and can crash your whole program.
Separate paths
Without exceptions, the flow of a program is fairly easy to visualize: you call a function, it returns a value.
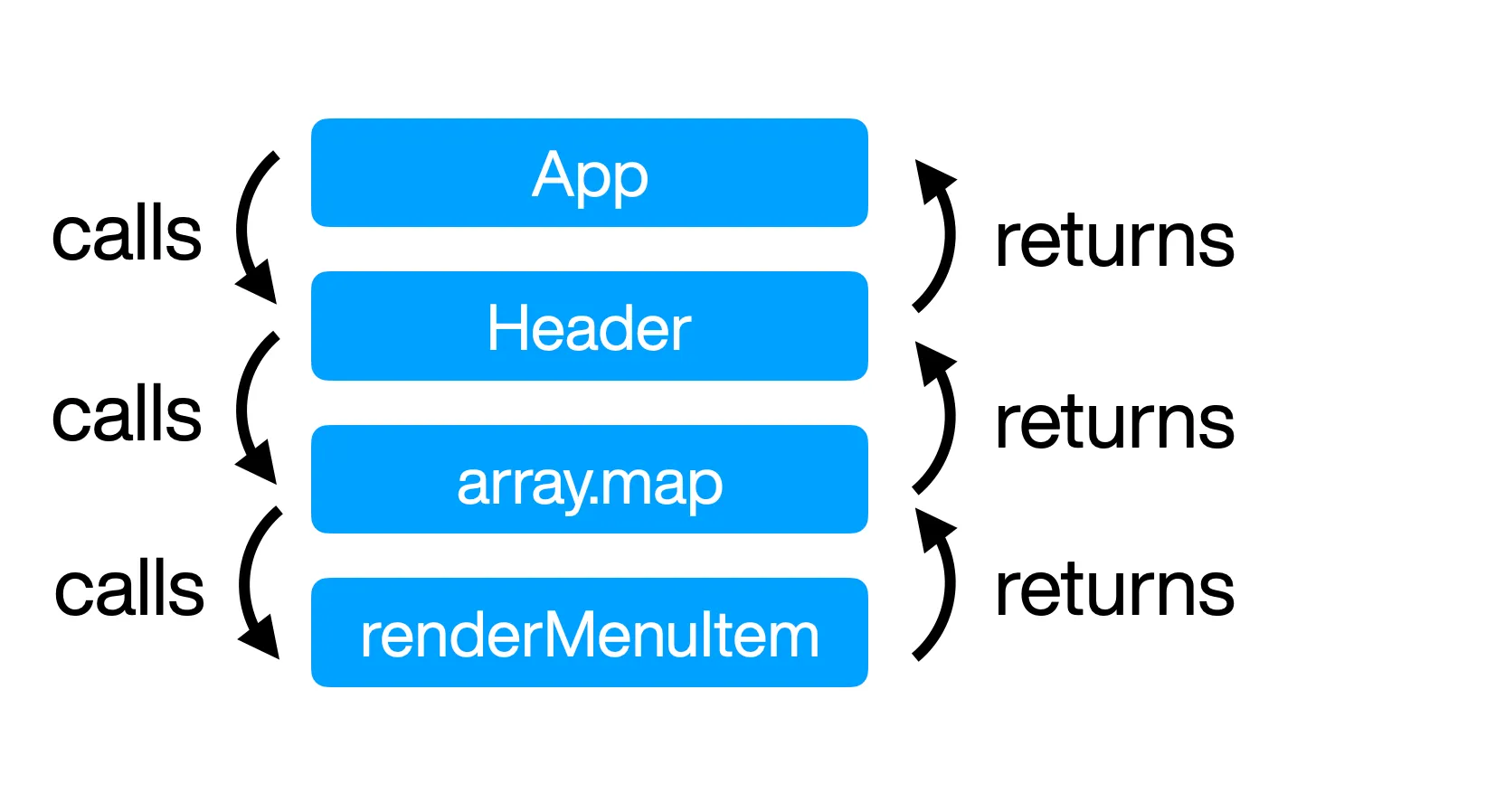
When you add exceptions to the mix, the nominal case is treated as expected while creating a path for other situations. When you throw an exception, the program ejects and crawls up the call stack until it finds a try/catch block.

This behavior is useful, as some intermediate callers in the stack might need to be agnostic about what happens inside. But it also brings mental overhead: on top of the regular flow, you have to remember all the possible exceptions at any point in the call stack.
Tracking errors
Some languages, most notably Java, have a way to help by tracking exceptions in the type system, which reduces the overhead:
While this is a nice feature, it still forces you to create two codepaths wherever a function can fail: one for the nominal case, one for the exception. We don’t have a way to pass the computation outcome around as a value, as exceptions are tightly coupled with the method, though defined separately.
The TypeScript case
TypeScript is built on top JavaScript, a notoriously dynamic language. So dynamic in fact that the following are all valid:
You can throw a promise, and React actually uses that one weird trick™ for its Suspense API so that a try/catch block can render the loader and wait for the promise. This is all very smart and fun but this particular “you can throw anything” principle ruins the one thing we’d need: to be able to type exceptions in TypeScript.
Because you can throw any type of value, you can’t know the type of the value a catch block can receive; it can only be unknown, leaving the caller guessing what kind of error it could be. This approach doesn’t scale, as it’s impossible for every member of a team to know every line of code that can run behind the scenes when calling a function.
It’s even the case with promises, because throwing in a then or catch callback outputs a rejected promise with the thrown value, which can be anything. That’s why Promise<T> only holds the type parameter for the fulfilled case.
Due to this limitation, it’s easy to struggle to type and track errors across a codebase.
Most errors are part of your domain
When building an app, you can sort errors in two categories:
- Expected errors, such as when an invalid value is submitted for which you have a specified response
- Unexpected errors, for a failure in the system you couldn’t predict
Exceptions shine in the latter, but we overuse them for the former: you might not want to interrupt the whole execution flow or have to use a try/catch block for those. In this situation using exceptions creates noise in the codebase, as we write additional code just to fit errors in a construct that might not be ideal: an error isn't always an exception.
Ergonomics
Let’s use a basic example:
The parseAndDivide function can throw either DivideByZeroError, SyntaxError, or IntOverflowError, but none of them appear in its type signature. If I want to call it, I need to go over all the underlying functions to know what to expect:
On top of that, if I simply want to use a default and ignore the error, the try ergonomics forces us to reassign values:
Result type to the rescue
If we look at some typed functional languages (and we definitely should), we find a type that’s called Result (or Either , which is the same with worse naming and type parameters in the wrong order, don't @ me ¯\_(ツ)_/¯). This type is the following:
A result value has two possible states:
It’s a data structure that represents the success of a computation. On the type level, you only know that it’s the result of an operation that can fail. From the type itself, you don’t know the exact state—you only know all of the possibilities.
It doesn’t seem like much, but it allows for a pretty powerful thing: carrying the computation results around as regular values, meaning a function can return a result, which can be passed as an argument, stored, you name it.
Let’s take a parseInt function. It can fail for two reasons: invalid input and integer overflow. With the result type, the function shows every possible outcome immediately, right in its signature.
It also clarifies at the type level where in the call stack errors are handled: if your function receives a result, you need to deal with it; if it receives a number , it’s taken care of.
How can I use result types in my codebase?
Glad you asked! Last year, we open sourced a library called Boxed to bring the Result type, along with some other niceties, to TypeScript.
You can create a result value:
They come with a lot of useful methods to help you keep your code expressive and closer to the domain:
With this code, the type-system automatically infers all the possible errors that can happen in a given codepath.
As to ergonomics, consuming the result looks like the following example:
If I want to ignore the error and fallback to a default value:
If I want to log the error but continue the flow:
To improve the DX, we’ve made the library compatible with exhaustiveness checks in TypeScript (and most notably with ts-pattern):
And that’s about it! The result type is a very powerful tool to make error management way easier in multiple ways: reducing mental overhead, lowering code complexity, and improving the type quality.
Hope you liked this article!
What to do next?
➡️ Check out Boxed: https://swan-io.github.io/boxed/
➡️ See how we use it internally (our frontend is open source!): https://github.com/swan-io/swan-partner-frontend

Summary
Customer stories
How Europe’s leading business platforms use Swan







.svg)




.svg)










%201.svg)


500+
Lorem ipsum dolor sit
Lorem ipsum dolor sit amet, consectetur adipiscing elit.
500+
Lorem ipsum dolor sit
Lorem ipsum dolor sit amet, consectetur adipiscing elit.
500+
Lorem ipsum dolor sit
Lorem ipsum dolor sit amet, consectetur adipiscing elit.
To use Apple Pay you need a supported card from a participating card issuer. To check if your card is compatible with Apple Pay, contact your card issuer. Apple Pay is not available in all markets. View Apple Pay countries and regions. Features are subject to change. Some features, applications, and services may not be available in all regions or all languages and may require specific hardware and software. For more information, see Feature Availability.



